
Real-Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model

 ,
,  ,
,  , , and
, , and 
Abstract
:1. Introduction
- A lightweight proposed model where there is no need to apply as much preprocessing which involves filtering, enhancement of images, etc.;
- A labeled dataset in both Pascal VOC and YOLO format;
- This is the first gesture recognition model that is dedicated to the mentioned gestures using YOLOv3. We use YOLOv3 as it is faster, stronger, and more reliable compared to other deep learning models. By using YOLOv3, our hand gesture recognition system has achieved a high accuracy even in a complex environment, and it successfully detected gestures even in low-resolution picture mode;
- The trained model can be used for real-time detection, it can be used for static hand images, and it also can detect gestures from video feed.
2. Related Work
3. Material and Methods
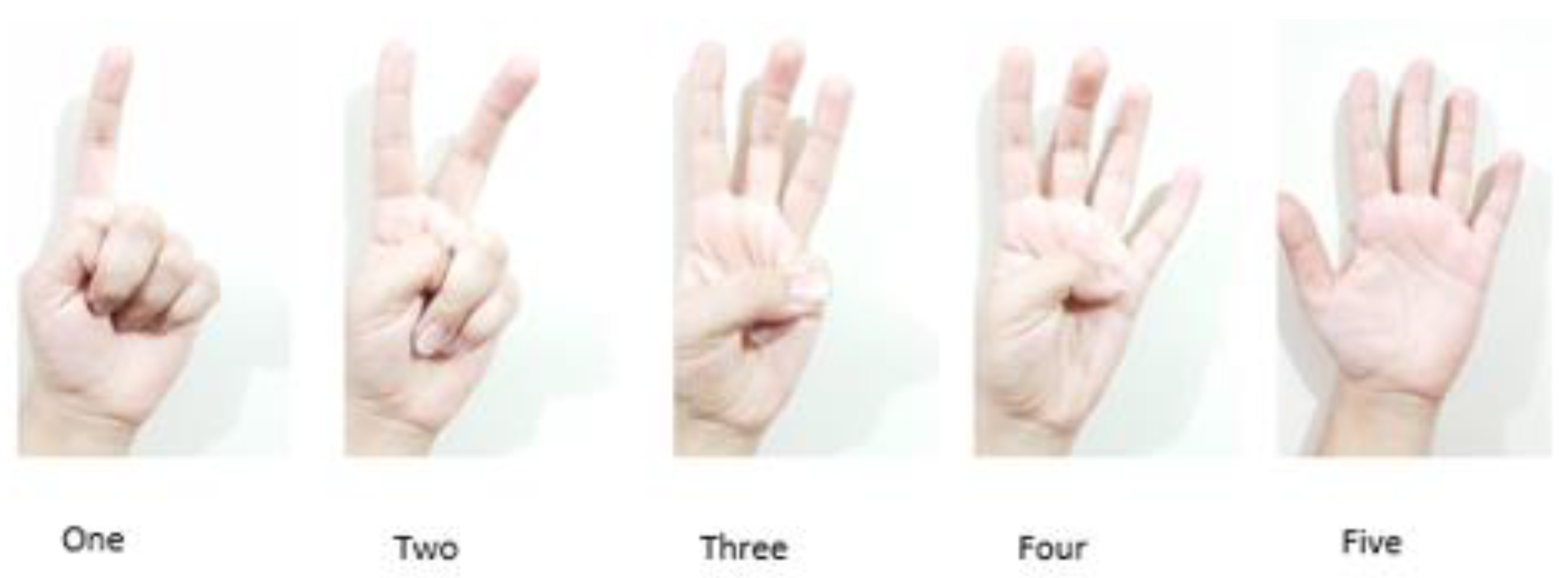
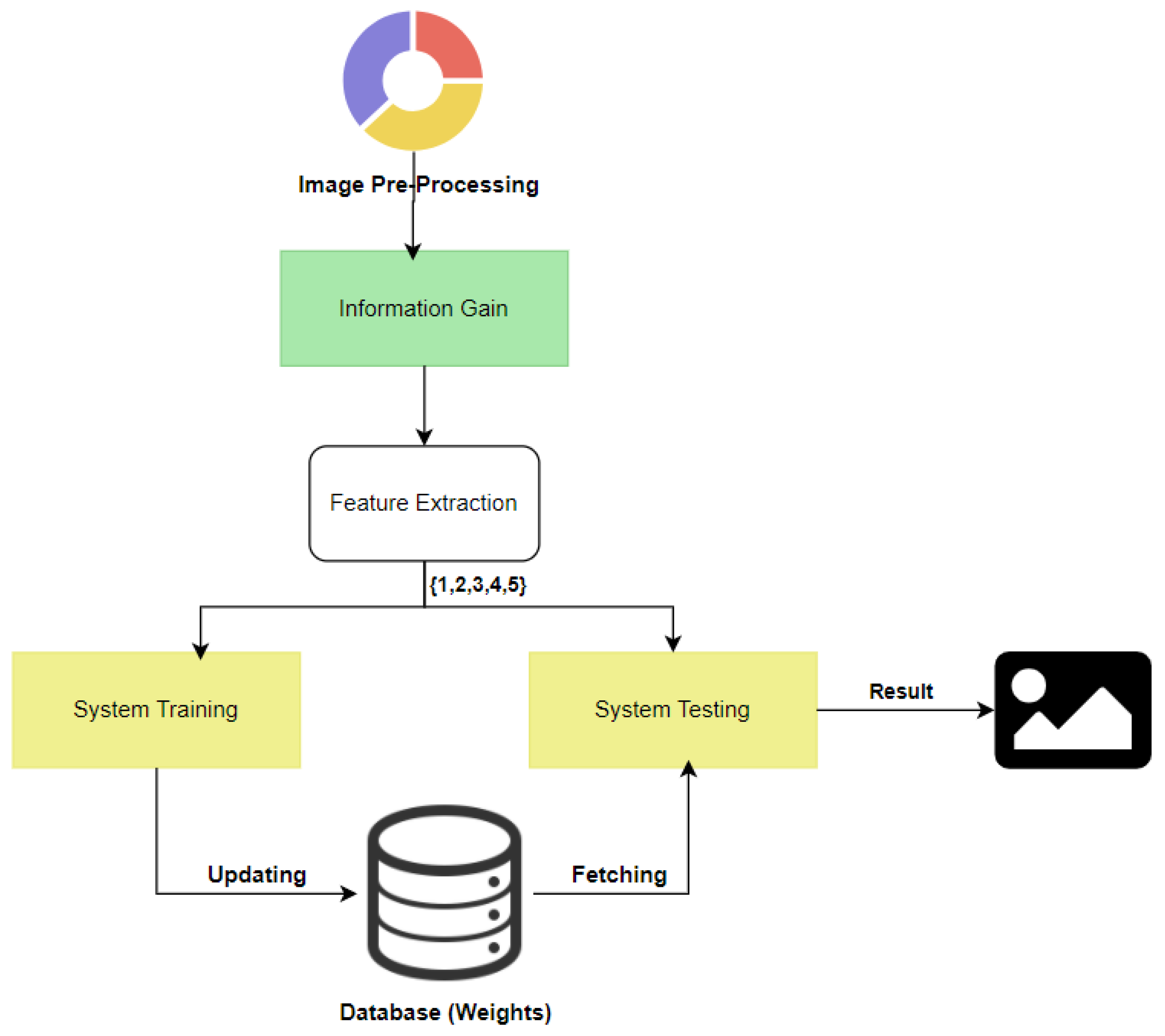
3.1. Dataset
3.2. Data Preprocessing
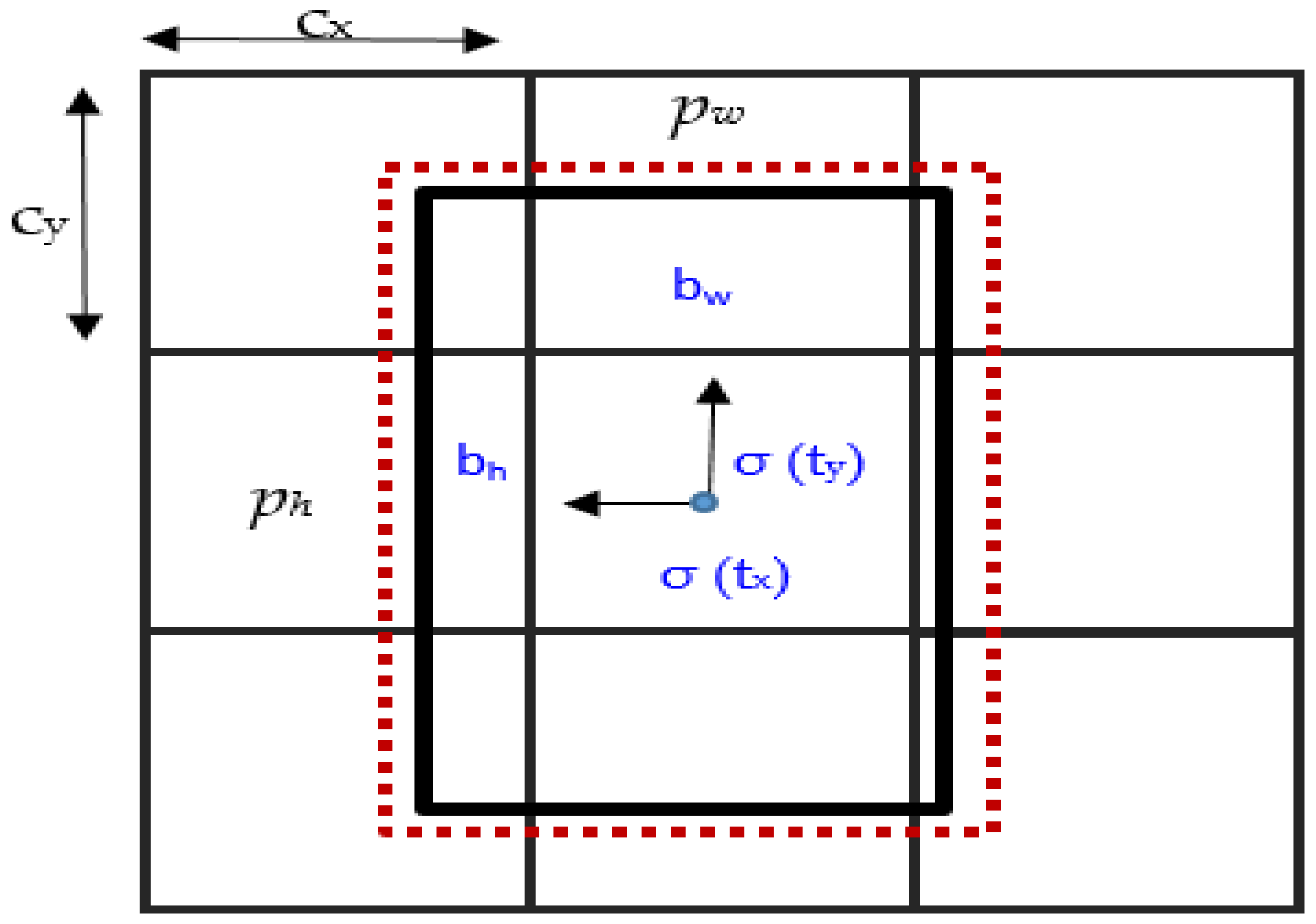
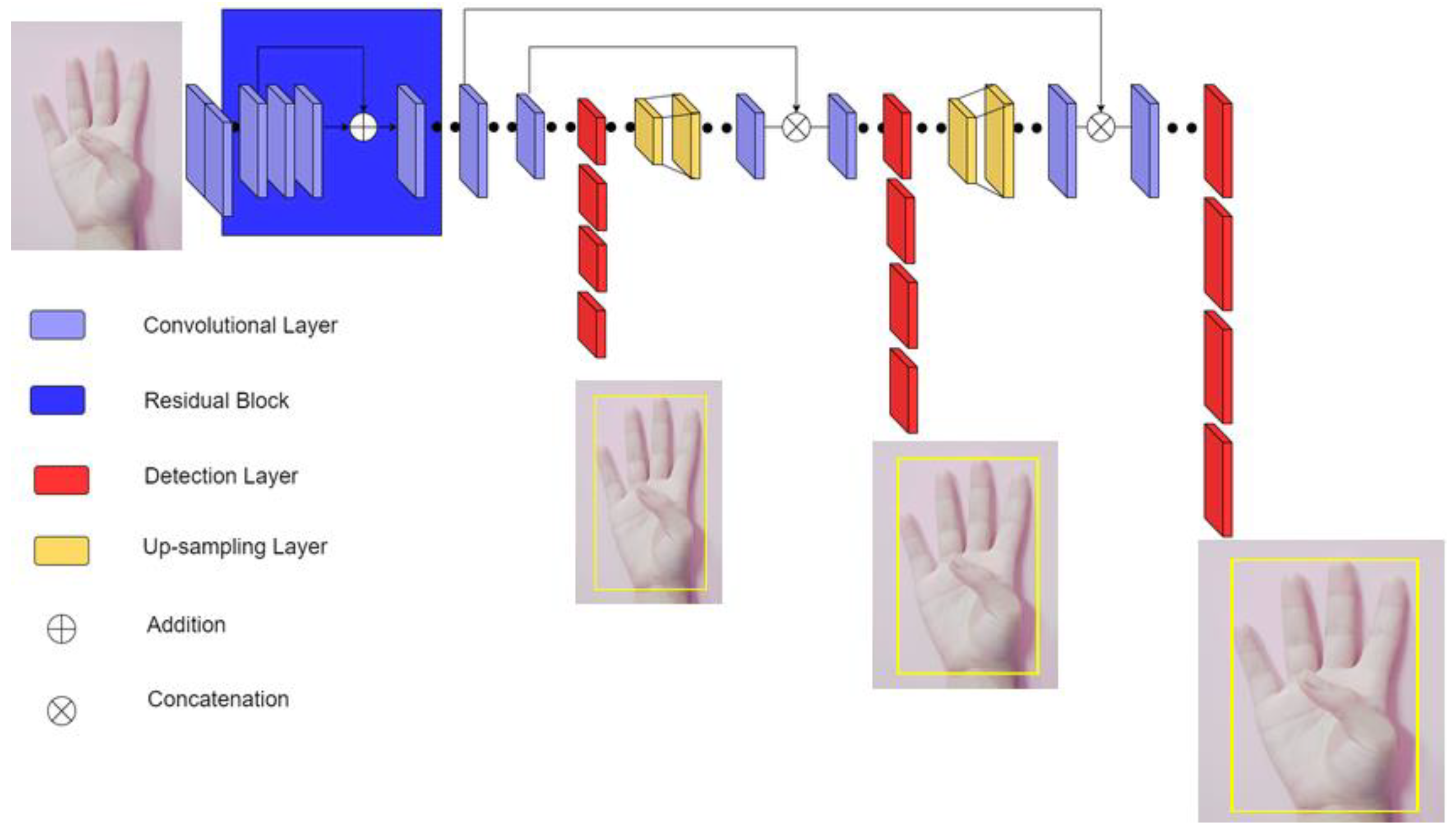
3.3. Proposed Method
3.4. Implementation
4. Results
4.1. Environmental Setup
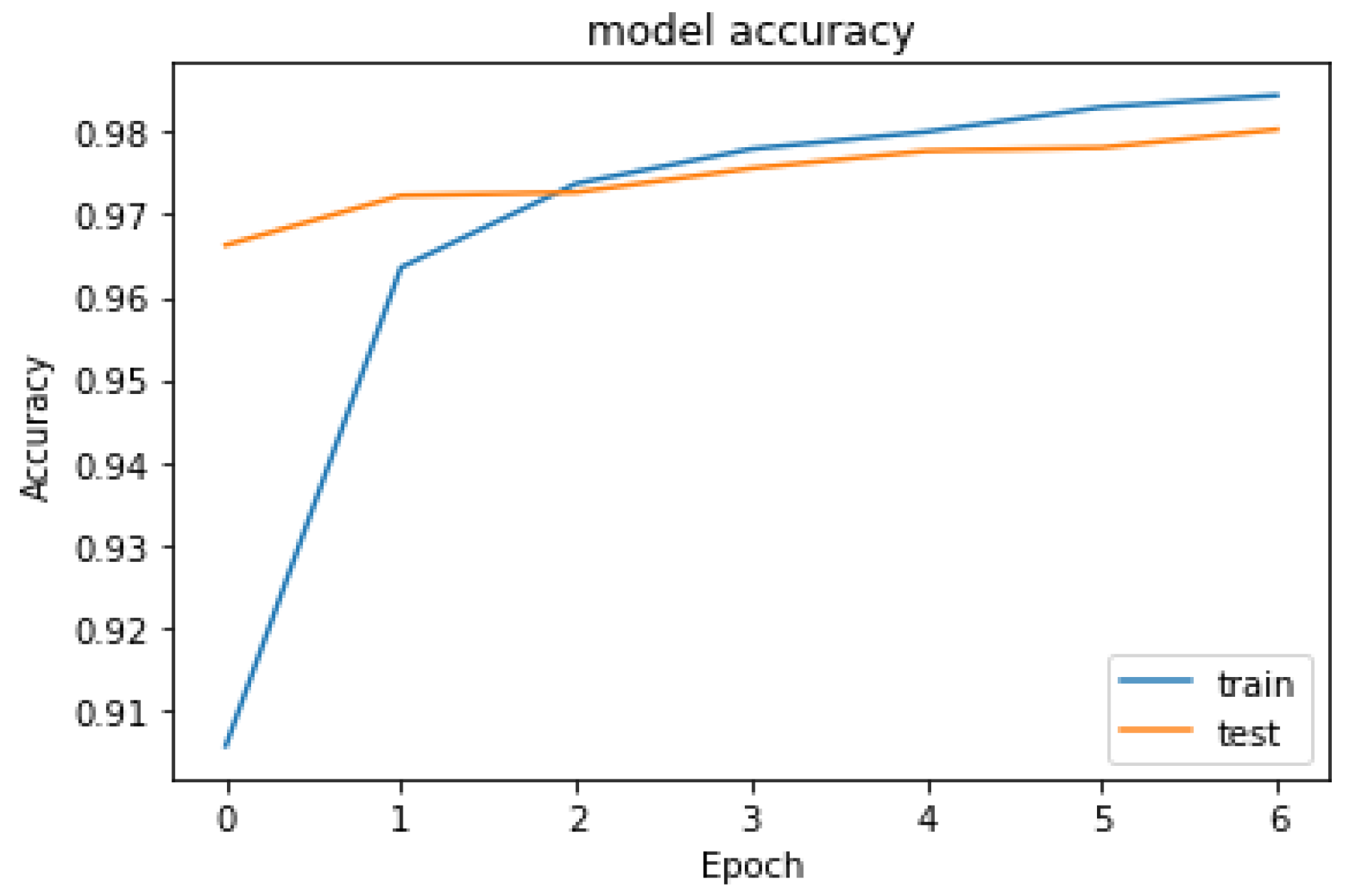
4.2. Results and Performance of YOLOv3
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fang, Y.; Wang, K.; Cheng, J.; Lu, H. A Real-Time Hand Gesture Recognition Method. In Proceedings of the Multimedia and Expo, IEEE International Conference On Multimedia and Expo, Beijing, China, 2–5 July 2007. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand Gesture Recognition Based on Computer Vision: A Review of Techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef]
- Al-Hammadi, M.; Muhammad, G.; Abdul, W.; Alsulaiman, M.; Bencherif, M.A.; Alrayes, T.S.; Mekhtiche, M.A. Deep learning-based approach for sign language gesture recognition with efficient hand gesture representation. IEEE Access 2020, 8, 192527–192542. [Google Scholar] [CrossRef]
- Vaitkevičius, A.; Taroza, M.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R.; Woźniak, M. Recognition of american sign language gestures in a virtual reality using leap motion. Appl. Sci. 2019, 9, 445. [Google Scholar] [CrossRef] [Green Version]
- Rezende, T.M.; Almeida, S.G.M.; Guimarães, F.G. Development and validation of a brazilian sign language database for human gesture recognition. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Žemgulys, J.; Raudonis, V.; Maskeliūnas, R.; Damaševičius, R. Recognition of basketball referee signals from real-time videos. J. Ambient Intell. Humaniz. Comput. 2020, 11, 979–991. [Google Scholar] [CrossRef]
- Afza, F.; Khan, M.A.; Sharif, M.; Kadry, S.; Manogaran, G.; Saba, T.; Ashraf, I.; Damaševičius, R. A framework of human action recognition using length control features fusion and weighted entropy-variances based feature selection. Image Vision Comput. 2021, 106, 104090. [Google Scholar] [CrossRef]
- Nikolaidis, A.; Pitas, I. Facial feature extraction and pose determination. Pattern Recognit. 2000, 33, 1783–1791. [Google Scholar] [CrossRef]
- Kulikajevas, A.; Maskeliunas, R.; Damaševičius, R. Detection of sitting posture using hierarchical image composition and deep learning. PeerJ Comput. Sci. 2021, 7, e442. [Google Scholar] [CrossRef] [PubMed]
- Ryselis, K.; Petkus, T.; Blažauskas, T.; Maskeliūnas, R.; Damaševičius, R. Multiple kinect based system to monitor and analyze key performance indicators of physical training. Hum. Centric Comput. Inf. Sci. 2020, 10, 51. [Google Scholar] [CrossRef]
- Huu, P.N.; Minh, Q.T.; The, H.L. An ANN-based gesture recognition algorithm for smart-home applications. KSII Trans. Internet Inf. Syst. 2020, 14, 1967–1983. [Google Scholar] [CrossRef]
- Abraham, L.; Urru, A.; Normani, N.; Wilk, M.P.; Walsh, M.; O’Flynn, B. Hand Tracking and Gesture Recognition Using Lensless Smart Sensors. Sensors 2018, 18, 2834. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, S.; Cho, S.H. Hand Gesture Recognition Using an IR-UWB Radar with an Inception Module-Based Classifier. Sensors 2020, 20, 564. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.-H.; Kwang-Seok Hong, K.-S. Game interface using hand gesture recognition. In Proceedings of the 5th International Conference on Computer Sciences and Convergence Information Technology, Seoul, Korea, 30 November–2 December 2010. [Google Scholar] [CrossRef]
- Alkemade, R.; Verbeek, F.J.; Lukosch, S.G. On the efficiency of a VR hand gesture-based interface for 3D object manipulations in conceptual design. Int. J. Hum. Comput. Interact. 2017, 33, 882–901. [Google Scholar] [CrossRef]
- Lee, Y.S.; Sohn, B. Immersive gesture interfaces for navigation of 3D maps in HMD-based mobile virtual environments. Mob. Inf. Syst. 2018, 2018, 2585797. [Google Scholar] [CrossRef] [Green Version]
- Del Rio Guerra, M.S.; Martin-Gutierrez, J.; Acevedo, R.; Salinas, S. Hand gestures in virtual and augmented 3D environments for down syndrome users. Appl. Sci. 2019, 9, 2641. [Google Scholar] [CrossRef] [Green Version]
- Moschetti, A.; Fiorini, L.; Esposito, D.; Dario, P.; Cavallo, F. Toward an unsupervised approach for daily gesture recognition in assisted living applications. IEEE Sens. J. 2017, 17, 8395–8403. [Google Scholar] [CrossRef]
- Mezari, A.; Maglogiannis, I. An easily customized gesture recognizer for assisted living using commodity mobile devices. J. Healthc. Eng. 2018, 2018, 3180652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Negin, F.; Rodriguez, P.; Koperski, M.; Kerboua, A.; Gonzàlez, J.; Bourgeois, J.; Bremond, F. PRAXIS: Towards automatic cognitive assessment using gesture recognition. Expert Syst. Appl. 2018, 106, 21–35. [Google Scholar] [CrossRef] [Green Version]
- Kaczmarek, W.; Panasiuk, J.; Borys, S.; Banach, P. Industrial robot control by means of gestures and voice commands in off-line and on-line mode. Sensors 2020, 20, 6358. [Google Scholar] [CrossRef]
- Neto, P.; Simão, M.; Mendes, N.; Safeea, M. Gesture-based human-robot interaction for human assistance in manufacturing. Int. J. Adv. Manuf. Technol. 2019, 101, 119–135. [Google Scholar] [CrossRef]
- Young, G.; Milne, H.; Griffiths, D.; Padfield, E.; Blenkinsopp, R.; Georgiou, O. Designing mid-air haptic gesture controlled user interfaces for cars. In Proceedings of the ACM on Human-Computer Interaction, 4(EICS), Article No. 81, Honolulu, HI, USA, 25–30 April 2020. [Google Scholar] [CrossRef]
- Yu, H.; Fan, X.; Zhao, L.; Guo, X. A novel hand gesture recognition method based on 2-channel sEMG. Technol. Health Care 2018, 26, 205–214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef] [Green Version]
- Kulikajevas, A.; Maskeliūnas, R.; Damaševičius, R.; Ho, E.S.L. 3D object reconstruction from imperfect depth data using extended yolov3 network. Sensors 2020, 20, 2025. [Google Scholar] [CrossRef] [Green Version]
- Ni, Z.; Chen, J.; Sang, N.; Gao, C.; Liu, L. Light YOLO for High-Speed Gesture Recognition. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar] [CrossRef]
- Chen, L.; Fu, J.; Wu, Y.; Li, H.; Zheng, B. Hand Gesture Recognition Using Compact CNN via Surface Electromyography Signals. Sensors 2020, 20, 672. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Colli-Alfaro, J.G.; Ibrahim, A.; Trejos, A.L. Design of User-Independent Hand Gesture Recognition Using Multilayer Perceptron Networks and Sensor Fusion Techniques. In Proceedings of the IEEE 16th International Conference on Rehabilitation Robotics (ICORR), Toronto, ON, Canada, 24–28 June 2019; pp. 1103–1108. [Google Scholar] [CrossRef]
- Elmezain, M.; Al-Hamadi, A.; Appenrodt, J.; Michaelis, B. A hidden markov model-based isolated and meaningful hand gesture recognition. Int. J. Electr. Comput. Syst. Eng. 2009, 3, 156–163. [Google Scholar]
- Nyirarugira, C.; Choi, H.-R.; Kim, J.; Hayes, M.; Kim, T. Modified levenshtein distance for real-time gesture recognition. In Proceedings of the 6th International Congress on Image and Signal Processing (CISP), Hangzhou, China, 16–18 December 2013. [Google Scholar] [CrossRef]
- Albawi, S.; Bayat, O.; Al-Azawi, S.; Ucan, O.N. Social Touch Gesture Recognition Using Convolutional Neural Network. Comput. Intell. Neurosci. 2018, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The Application of Improved YOLO V3 in Multi-Scale Target Detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef] [Green Version]
- Saqib, S.; Ditta, A.; Khan, M.A.; Kazmi, S.A.R.; Alquhayz, H. Intelligent dynamic gesture recognition using CNN empowered by edit distance. Comput. Mater. Contin. 2020, 66, 2061–2076. [Google Scholar] [CrossRef]
- Al-Hammadi, M.; Muhammad, G.; Abdul, W.; Alsulaiman, M.; Bencherif, M.A.; Mekhtiche, M.A. Hand gesture recognition for sign language using 3DCNN. IEEE Access 2020, 8, 79491–79509. [Google Scholar] [CrossRef]
- Do, N.; Kim, S.; Yang, H.; Lee, G. Robust hand shape features for dynamic hand gesture recognition using multi-level feature LSTM. Appl. Sci. 2020, 10, 6293. [Google Scholar] [CrossRef]
- Elboushaki, A.; Hannane, R.; Afdel, K.; Koutti, L. MultiD-CNN: A multi-dimensional feature learning approach based on deep convolutional networks for gesture recognition in RGB-D image sequences. Expert Syst. Appl. 2020, 139. [Google Scholar] [CrossRef]
- Peng, Y.; Tao, H.; Li, W.; Yuan, H.; Li, T. Dynamic gesture recognition based on feature fusion network and variant ConvLSTM. IET Image Process. 2020, 14, 2480–2486. [Google Scholar] [CrossRef]
- Tan, Y.S.; Lim, K.M.; Lee, C.P. Hand gesture recognition via enhanced densely connected convolutional neural network. Expert Syst. Appl. 2021, 175. [Google Scholar] [CrossRef]
- Tran, D.; Ho, N.; Yang, H.; Baek, E.; Kim, S.; Lee, G. Real-time hand gesture spotting and recognition using RGB-D camera and 3D convolutional neural network. Appl. Sci. 2020, 10, 722. [Google Scholar] [CrossRef] [Green Version]
- Rahim, M.A.; Islam, M.R.; Shin, J. Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion. Appl. Sci. 2019, 9, 3790. [Google Scholar] [CrossRef] [Green Version]
- Mambou, S.; Krejcar, O.; Maresova, P.; Selamat, A.; Kuca, K. Novel Hand Gesture Alert System. Appl. Sci. 2019, 9, 3419. [Google Scholar] [CrossRef] [Green Version]
- Ashiquzzaman, A.; Lee, H.; Kim, K.; Kim, H.-Y.; Park, J.; Kim, J. Compact Spatial Pyramid Pooling Deep Convolutional Neural Network Based Hand Gestures Decoder. Appl. Sci. 2020, 10, 7898. [Google Scholar] [CrossRef]
- Benitez-Garcia, G.; Prudente-Tixteco, L.; Castro-Madrid, L.C.; Toscano-Medina, R.; Olivares-Mercado, J.; Sanchez-Perez, G.; Villalba, L.J.G. Improving Real-Time Hand Gesture Recognition with Semantic Segmentation. Sensors 2021, 21, 356. [Google Scholar] [CrossRef] [PubMed]
- Bradski, G. The OpenCV Library. Dr Dobb’s J. Softw. Tools 2000, 25, 120–125. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Qassim, H.; Verma, A.; Feinzimer, D. Compressed residual-VGG16 CNN model for big data places image recognition. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 169–175. [Google Scholar] [CrossRef]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Fong, S.; Liang, J.; Fister, I.; Fister, I.; Mohammed, S. Gesture Recognition from Data Streams of Human Motion Sensor Using Accelerated PSO Swarm Search Feature Selection Algorithm. J. Sens. 2015, 2015, 205707. [Google Scholar] [CrossRef]
- Yan, S.; Xia, Y.; Smith, J.S.; Lu, W.; Zhang, B. Multiscale Convolutional Neural Networks for Hand Detection. Appl. Comput. Intell. Soft Comput. 2017, 2017, 9830641. [Google Scholar] [CrossRef] [Green Version]
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust Part-Based Hand Gesture Recognition Using Kinect Sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Pedoeem, J.; Huang, R. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Sismananda, P.; Abdurohman, M.; Putrada, A.G. Performance Comparison of Yolo-Lite and YoloV3 Using Raspberry Pi and MotionEyeOS. In Proceedings of the 8th International Conference on Information and Communication Technology (ICoICT), Yogyakarta, Indonesia, 4–5 August 2020; pp. 1–7. [Google Scholar]
- Połap, D. Human-machine interaction in intelligent technologies using the augmented reality. Inf. Technol. Control 2018, 47, 691–703. [Google Scholar] [CrossRef] [Green Version]
- Žemgulys, J.; Raudonis, V.; Maskeliunas, R.; Damaševičius, R. Recognition of basketball referee signals from videos using histogram of oriented gradients (HOG) and support vector machine (SVM). Procedia Comput. Sci. 2018, 130, 953–960. [Google Scholar] [CrossRef]
- Wozniak, M.; Wieczorek, M.; Silka, J.; Polap, D. Body pose prediction based on motion sensor data and recurrent neural network. IEEE Trans. Ind. Inform. 2021, 17, 2101–2111. [Google Scholar] [CrossRef]
- Maskeliunas, R.; Damaševicius, R.; Segal, S. A review of internet of things technologies for ambient assisted living environments. Future Internet 2019, 11, 259. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Zhou, Y.; Zhang, L.; Peng, Y.; Hu, X.; Peng, H.; Cai, X. Mixed YOLOv3-LITE: A Lightweight Real-Time Object Detection Method. Sensors 2020, 20, 1861. [Google Scholar] [CrossRef] [Green Version]
- Awan, M.J.; Rahim, M.S.M.; Salim, N.; Mohammed, M.A.; Garcia-Zapirain, B.; Abdulkareem, K.H. Efficient Detection of Knee Anterior Cruciate Ligament from Magnetic Resonance Imaging Using Deep Learning Approach. Diagnostics 2021, 11, 105. [Google Scholar] [CrossRef] [PubMed]
- Mastoi, Q.; Memon, M.S.; Lakhan, A.; Mohammed, M.A.; Qabulio, M.; Al-Turjman, F.; Abdulkareem, K.H. Machine learning-data mining integrated approach for premature ventricular contraction prediction. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Abdulkareem, K.H.; Mostafa, S.A.; Ghani, M.K.A.; Maashi, M.S.; Garcia-Zapirain, B.; Oleagordia, I.; Alhakami, H.; Al-Dhief, F.T. Voice pathology detection and classification using convolutional neural network model. Appl. Sci. 2020, 10, 3723. [Google Scholar] [CrossRef]
- Kashinath, S.A.; Mostafa, S.A.; Mustapha, A.; Mahdin, H.; Lim, D.; Mahmoud, M.A.; Mohammed, M.A.; Al-Rimy, B.A.S.; Fudzee, M.F.M.; Yang, T.J. Review of Data Fusion Methods for Real-Time and Multi-Sensor Traffic Flow Analysis. IEEE Access 2021, 9, 51258–51276. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
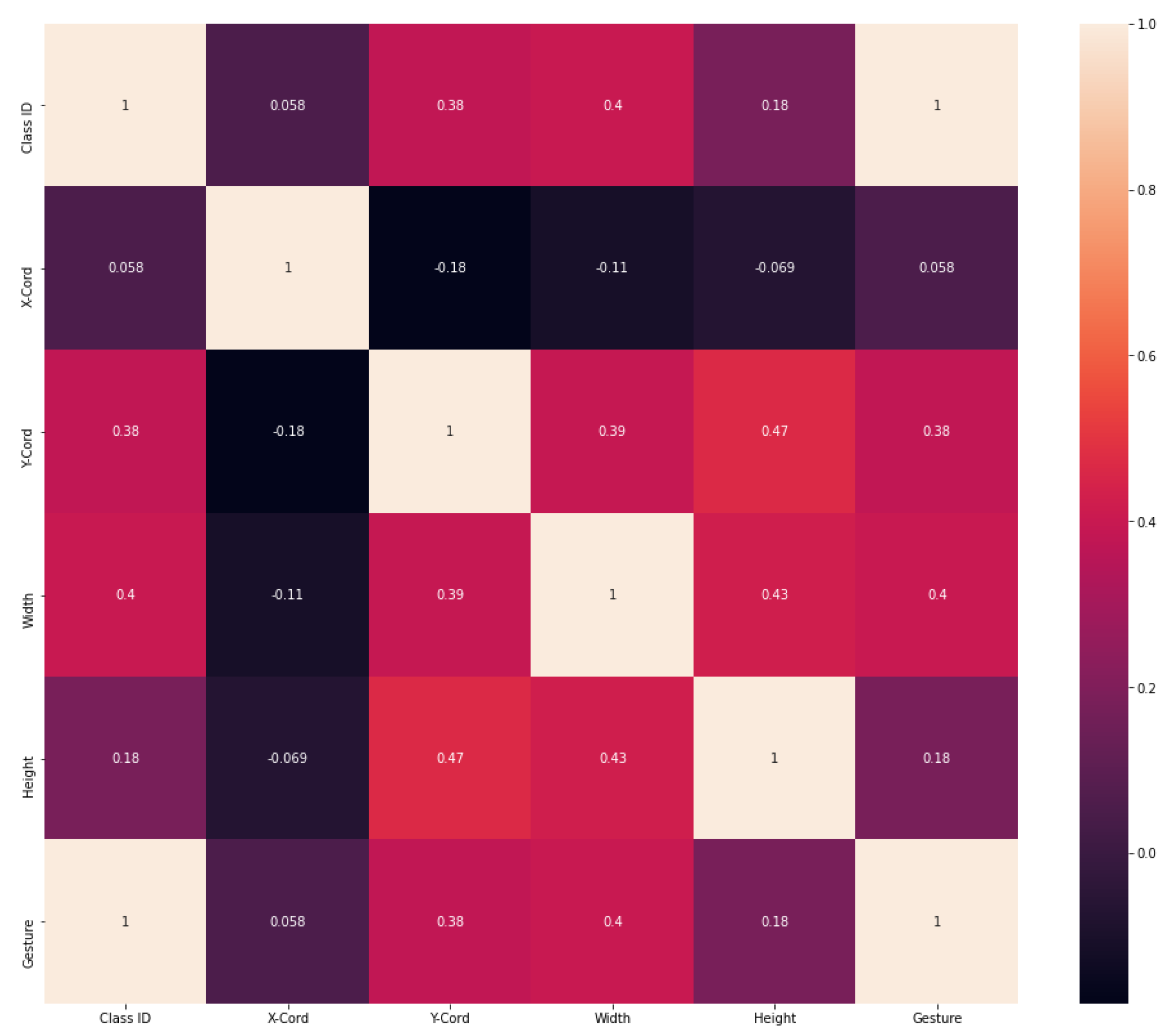
| Class ID | X-Cord | Y-Cord | Width | Height |
|---|---|---|---|---|
| 0 | 0.531771 | 0.490234 | 0.571875 | 0.794531 |
| 1 | 0.498437 | 0.533203 | 0.571875 | 0.905469 |
| 2 | 0.523438 | 0.579297 | 0.613542 | 0.819531 |
| 3 | 0.526563 | 0.564453 | 0.473958 | 0.819531 |
| 4 | 0.498611 | 0.587891 | 0.977778 | 0.792969 |
| Layer (Type) | Output Shape | Parameters |
|---|---|---|
| Conv2d_133 (Conv2D) | (None, 126, 254, 64) | 1792 |
| Max_pooling_132 (Max Pooling) | (None, 63, 127, 64) | 0 |
| Conv2d_134 (Conv2D) | (None, 61, 125, 64) | 36928 |
| Max_pooling_133 (Max Pooling) | (None, 20, 41, 64, 0) | 0 |
| Conv2d_135 (Conv2D) | (None, 18, 39, 64) | 36928 |
| Max_pooling_134 (Max Pooling) | (None, 6, 13, 64) | 0 |
| Conv2d_136 (Conv2D) | (None, 4, 11, 64) | 36928 |
| Max_pooling_135 (Max Pooling) | (None, 1, 3, 64) | 0 |
| Flatten_33 (Flatten) | (None, 192) | 0 |
| Dense_151 (Dense) | (None, 128) | 24704 |
| Dropout_36 (Dropout) | (None, 128) | 0 |
| Dense_152 (Dense) | (None, 64) | 8256 |
| Dense_153 (Dense) | (None, 32) | 2080 |
| Dense_154 (Dense) | (None, 8) | 264 |
| Hyper Parameter | Value |
|---|---|
| Learning Rate | 0.001 |
| Epochs | 30 |
| No. of Classes | 5 |
| Algorithm | DarkNet-53 and YOLOv3 |
| Optimizer | Adam |
| Activation | Linear, Leaky |
| Filter Size | [64,128,256,512,1024] |
| Mask | 0–8 |
| Decay | 0.0005 |
| Models | Learning Rate | Images | Precision (%) | Recall (%) | F-1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| VGG16 | 0.001 | 216 | 93.45 | 87.45 | 90.3 | 85.68 |
| SGD | 0.1 | 216 | 70.95 | 98.37 | 82.4 | 77.98 |
| SSD | 0.0001 | 216 | 91.25 | 84.30 | 87.6 | 82.00 |
| YOLOv3 | 0.001 | 216 | 94.88 | 98.68 | 96.7 | 97.68 |
| Reference | Model | Dataset | Accuracy (%) |
|---|---|---|---|
| Chen et al. [28] | Labeling Algorithm Producing Palm Mask | 1300 images | 93% |
| Nyirarugira et al. [31] | Particle Swarm Movement (PSO), Longest Common Subsequence (LCS) | Gesture vocabulary | 86% |
| Albawi et al. [32] | Random Forest (RF) and Boosting Algorithms, Decision Tree Algorithm | 7805 gestures frames | 63% |
| Fong et al. [50] | Model Induction Algorithm, K-star Algorithm, Updated Naïve Bayes Algorithm, Decision Tree Algorithm | 50 different attributes total of 9000 data instance 7 videos | 76% |
| Yan et al. [51] | AdaBoost Algorithm, SAMME Algorithm, SGD Algorithm, Edgebox Algorithm | 5500 images for the testing and 5500 for the training set | 81.25% |
| Ren et al. [52] | FEMD Algorithm, Finger Detection Algorithm, Skeleton-Based Matching | 1000 cases | 93.20% |
| Proposed model | YOLOv3 | 216 images (Train) 15 images (Test) | 97.68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mujahid, A.; Awan, M.J.; Yasin, A.; Mohammed, M.A.; Damaševičius, R.; Maskeliūnas, R.; Abdulkareem, K.H. Real-Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model. Appl. Sci. 2021, 11, 4164. https://doi.org/10.3390/app11094164
Mujahid A, Awan MJ, Yasin A, Mohammed MA, Damaševičius R, Maskeliūnas R, Abdulkareem KH. Real-Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model. Applied Sciences. 2021; 11(9):4164. https://doi.org/10.3390/app11094164
Chicago/Turabian StyleMujahid, Abdullah, Mazhar Javed Awan, Awais Yasin, Mazin Abed Mohammed, Robertas Damaševičius, Rytis Maskeliūnas, and Karrar Hameed Abdulkareem. 2021. "Real-Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model" Applied Sciences 11, no. 9: 4164. https://doi.org/10.3390/app11094164